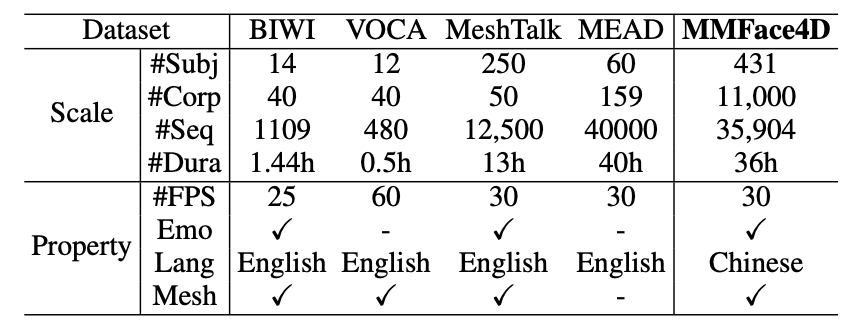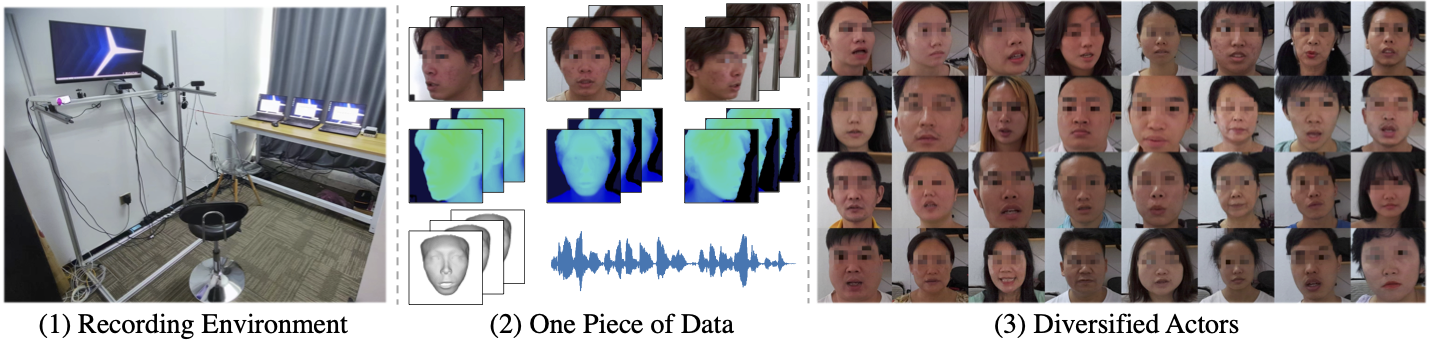
Capture Setup
We devise a capture system comprising three RGB-D cameras, one microphone, and one screen.
Each camera is placed at the height of 1.2 meters.
One camera shoots at the front of the face, the other two cameras shoot at the left and right sides with 45 degrees of angle.
The cameras are accurately aligned.
We leverage Azure Kinect Camera to capture RGB-D video. We record RGB video with a resolution of 1920 * 1080, and record depth video with a resolution of 640 * 576.
Before recording, we built a large-scale corpus with 11,000 sentences under different scenarios such as news broadcasting, conversation, and storytelling. Each sentence has an emotion label of seven categories (neutral, angry, disgust, happy, fear, sad, surprise). For the neutral emotion, we have 2000 sentences. For the other emotions, we have 1500 sentences. Each sentence of the corpus has 17 words on average. Our corpus covers each phoneme as evenly as possible.
Before recording, we built a large-scale corpus with 11,000 sentences under different scenarios such as news broadcasting, conversation, and storytelling. Each sentence has an emotion label of seven categories (neutral, angry, disgust, happy, fear, sad, surprise). For the neutral emotion, we have 2000 sentences. For the other emotions, we have 1500 sentences. Each sentence of the corpus has 17 words on average. Our corpus covers each phoneme as evenly as possible.